
Robots.txt یکی از مهمترین فایلهای وبسایت است که با کوچکترین اشتباهی در خصوص آن، تمام تلاشهای چند ساله شما در خصوص یک وبسایت ممکن است به هدر برود. با توجه به اهمیت این فایل در سئو تکنیکال و تعیین وضعیت جلوگیری از ایندکس صفحات سایت در گوگل، در این مطلب قصد داریم نحوه ساخت فایل Robots.txt را به شما عزیزان آموزش دهیم.
با ما همراه باشید.
فایل Robots.txt چیست؟
فایل روبوت Robots.txt، به فایلی در سایت گفته میشود که وضعیت دسترسی خزندههای گوگل، به بخشهای مختلف صفحات وبسایت را تعیین میکند. در درجه اول، میتوانید تمام مطالبی که نمیخواهید توسط گوگل بررسی و ایندکس شوند را در این فایل فهرست کنید. علاوه بر این، برای برخی از موتورهای جستجو (نه گوگل) تعیین کنید که فایلهای مجاز را چگونه ایندکس کنند. استفاده از این فایل باید توسط فرد حرفهای انجام شده و بههیچوجه توصیه نمیکنیم که بدون داشتن دانش کافی در این خصوص، خود شما شخصا برای ایجاد فایل و اضافه کردن آن به وبسایت، اقدام کنید.
نکته مهم: برخی از موتورهای جستجوگر از قوانین تعیین شده در فایل ربات تی اکس تی پیروی نمیکنند!! اما خوشبختانه گوگل یکی از آنها نیست. با توجه به این که در حال حاضر نیز اکثر وبسایتها برای حضور در نتایج گوگل در تلاش هستند، میتوان گفت که این فایل روبوت، برای بیشتر وبسایتها کاربردی و حائز اهمیت خواهد بود.
فایل Robots.txt سایت من کجاست؟
در صورتی فایل Robots.txt در پروندههای سایت شما موجود باشد، با وارد کردن آدرس Domain.com/robots.txt در مرورگر، تصویری مشابه با عکس زیر مشاهده خواهید کرد:

ظاهر فایل Robots.txt چگونه است؟
فرمت اصلی فایل Robots.txt به صورت زیر است:
[Sitemap: [URL location of sitemap
[User-agent: [bot identifier
[directive 1]
[directive 2]
[ … directive]
[User-agent: [another bot identifier
[directive 1]
[directive 2]
[ … directive]
اگر تاکنون متوجه حضور این فایل در بین پروندهای وبسایتتان نشدهاید، جای نگرانی نیست. چرا که در ادامه نحوه ساخت فایل Robots.txt را به شما آموزش خواهیم داد. اما قبل از شروع این آموزش، بهتر است در مورد هر یک از بخشها و دستورات این فایل صحبت کنیم.
User-agents
هر موتور جستجویی از چند User-agents تشکیل شده است. از میان هزاران User-agents، تنها چند مورد از آنها برای رتبهبندی سئو سایت کاربردی است که باید وضعیتشان در فایل روبوت مشخص شود. برخی از آنها عبارتاند از:
- گوگل: Googlebot
- تصاویر گوگل: (Google Images): Googlebot-Image
- بینگ: Bing bot
- یاهو: Slurp
- بایدو: Baidu spider
- DuckDuckGo :Duck Duck Bot
تمام User-agentsها به حروف بزرگ و کوچک حساس هستند. پس اگر قصد استفاده هر یک از آنها را دارید، لازم است دقیق همانطور که نوشته شدهاند، آنها را به کار بگیرید.
در صورتی که قصد دارید وضعیت تمام User-agentsها را به یک صورت تعیین کنید، میتوانید از (*) استفاده کنید. به عنوان مثال فرض کنید که میخواهید دسترسی تمام خزندهها به جز گوگل را مسدود کنید. در این صورت باید این قطعه کد را داخل فایل Robots.txt قرار دهید:
* : User-agent
/ : Disallow
User-agent: Googlebot
/ :Allow
به خاطر داشته باشید که برای هر User-agents باید به صورت مجزا از هم تعیین وضعیت کنید. اما در صورتی که برای یک User-agents چند وضعیت مختلف تعیین کنید، تمامی دستورات با یکدیگر ترکیب شده و اجرا میشوند.

Directives در فایل robots.txt
Directives به قوانینی گفته میشود که برای هر user-agents تعیین خواهد شد. در ادامه به کاربرد هر یک از دستوراتی که برای گوگل به کار برده میشوند، اشاره خواهیم کرد.
-
Disallow
از این دستورالعمل باید زمانی استفاده کنید که بخواهید دسترسی موتورهای جستجوگر را به فایلها و صفحاتی که در یک مسیر خاص قرار دارند، ببندید. به عنوان مثال اگر میخواهید تمام موتورهای جستجو به تمام پستهای بخش وبلاگ دسترسی نداشته باشند، فایل robots.txt به شکل زیر خواهدبود:
* : User-agent
Disallow: /blog
توجه: در صورتی که آدرس بعد از Disallow را درست تعریف نکنید، این دستور توسط موتورهای جستجو، نادیده گرفته خواهد شد.
-
Allow
از این دستور باید زمانی استفاده کنید که میخواهید دسترسی لازم برای برخی از صفحات یا زیرشاخهها (subdirectory) را برای موتور جستجوگر ایجاد کنید. حتی اگر صفحه یا زیرشاخه در یک disallowed directory قرار گرفته باشد، باز هم با استفاده از این دستور، دسترسی به آن امکانپذیر خواهد شد. لازم به توضیح است که هم گوگل و هم بینگ از این دستور پشتیبانی میکنند.
به عنوان مثال اگر میخواهید دسترسی موتورهای جستجو به تمامی پستهای وبلاگ مسدود شود به جز یکی، باید قطعه کد زیر را در فایل robots.txt قرار دهید:
User-agent: *
Disallow: /blog
Allow: /blog/allowed-post
منظور از allowed-post، نام پست در بخش وبلاگ سایت است.
توجه: در صورتی که آدرس بعد از Allow را درست تعریف نکنید، این دستور توسط موتورهای جستجو، نادیده گرفته خواهدشد.
در صورتی که از دستورات disallow و allow به درستی استفاده نکنید، این احتمال وجود دارد که در تضاد باهم قرار گیرند. به عنوان مثال:
User-agent: *
/Disallow: /blog
Allow: /blog
در این شرایط، گوگل و بینگ دستوری را اجرا میکنند که تعداد کاراکتر بیشتری داشته باشد. به طور مثال در این مورد به خصوص، دستور Disallow اجرا میشود.در صورتی که تعداد کاراکترهای هر دو دستور یکی باشد، دستوری اجرا میشود که آخر از همه آمده باشد. در این مورد، دستور Allow اجرا خواهد شد.
به خاطر داشته باشید که تنها گوگل و بینگ از این شرایط پیروی میکنند. سایر موتورهای جستجو دستور اول در اولویتشان قرار خواهد داشت. بنابراین برای دیگر موتورهای جستجو، دستور disallow اجرا خواهد شد.
نقشه سایت (Sitemap)
از این دستور برای تعیین موقعیت Sitemap استفاده میکنید. نقشه سایت، به فایلی گفته میشود که شامل تمام صفحاتی است که میخواهید توسط موتورهای جستجو بررسی و ایندکس شوند.
Sitemap: https://www.domain.com/sitemap.xml
*:User-agent
/Disallow: /blog
/Allow: /blog/post-title
در صورتی که موقعیت نقشه سایت را از طریق سرچ کنسول برای گوگل تعیین کردهاید، پس این قطعه کد اضافی است. اما برای سایر مورتوهای جستجو مانند بینگ، وجود این کد ضروری است. لازم به ذکر است که نباید این کد را برای هر user-agent تکرار کنید. بنابراین از این کد تنها یک بار، در ابتدا یا انتهای فایل robots.txt استفاده کنید.
به عنوان مثال:
Sitemap: https://www.domain.com/sitemap.xml
User-agent: Googlebot
/Disallow: /blog
/Allow: /blog/post-title
User-agent: Bingbot
/Disallow: /services
دستوراتی که نباید در فایل Robots.txt از آنها استفاده کنید
در ادامه دستوراتی را معرفی میکنیم که نباید از آنها برای گوگل در فایل روبوت استفاده کنید.
-
Crawl-delay
Crawl-delay همانطور که از نامش مشخص است، دستوری است که برای هر خزش یک مدت زمان مشخصی تاخیر به ثانیه در نظر میگیرد. به عنوان مثال زمانی که خزش رباتها در یک صفحه تمام میشود، خزندهها باید 5 ثانیه صبر کنند.
User-agent: Googlebot
Crawl-delay: 5
در حال حاضر گوگل از این دستور پشتیبانی نمیکند. اما استفاده از این دستور برای بینگ و Yandex موضوعیت خواهد داشت. هنگام استفاده از این دستور برای سایتهای بزرگ، لازم سات که دقت زیادی به خرج دهید. توضیح این که در صورتی که برای خزندهها، چنین تاخیری در نظر بگیرید، تعداد URLهایی که در یک روز خزندهها میتوانند بررسی کند به 17280 محدود خواهد شد. اما اگر سایت کوچکی دارید و پهنای باند برایتان اهمیت دارد، استفاده از این دستور مشکل خاصی ایجاد نخواهد کرد.
-
Noindex
Noindex یکی دیگر از تگهایی است که هیچ وقت به طور رسمی توسط گوگل پشتیبانی نشد. با این وجود اگر میخواهید از ایندکس مطالب بلاگ جلوگیری کنید، میتوانید از دستورات زیر در فایل Robots.txt استفاده کنید:
User-agent: Googlebot
/Noindex: /blog
در تاریخ 1 سپتامبر 2019 ، گوگل اعلام کرد که از این دستور پشتیبانی نمیکند. اگر میخواهید اجازه ایندکس شدن یک صفحه یا پروندهای از سایت را به گوگل ندهید، به جای استفاده از این دستور، از x‑robots HTTP header استفاده کنید.
-
Nofollow
این دستور هم هیچ وقت به صورت رسمی توسط گوگل پشتیبانی نشد. پیش از این دستور برای اینکه موتور جستجو لینکهای داخل یک صفحه یا مسیر خاص را دنبال نکند، به کار گرفته میشد. به عنوان مثال اگر میخواهید گوگل هیچ یک از لینکهای داخلی وبلاگ را دنبال نکند، باید از قطعه کد زیر استفاده کنید:
User-agent: Googlebot
/Nofollow: /blog
در تاریخ 1 سپتامبر 2019، گوگل رسما اعلام کرد که دیگر از این دستور پشتیبانی نمیکند. در نتیجه برای نوفالو کردن لینکها، میتوانید از تگ rel = “nofollow” استفاده کنید.
ساخت فایل Robots.txt برای چه وب سایتهایی ضروری است؟
ساخت فایل Robots.txt برای وب سایتهایی که تعداد صفحات زیادی دارند، ضروری است. چرا که با استفاده از دستورات گفته شده، میتوان کنترل بیشتری روی موتورهای جستجو و وضعیت ایندکس صفحات داشت. برخی از مزایای این فایل عبارتاند از:
- جلوگیری از بررسی محتوای تکراری توسط خزندهها
- خصوصی کردن بخشی از قسمتهای سایت
- جلوگیری از خزش صفحات جستجو داخلی سایت
- جلوگیری از سرریز شدن سرور
- جلوگیری از هدر رفت بودجه گوگل
- جلوگیری از نمایش برخی از عکسها و فیلمها در نتایج گوگل
البته لازم به ذکر است که هیچ تضمین صد در صدی مبنی بر این که صفحات مسدود شده سایت در نتایج گوگل ظاهر نشوند، وجود ندارد. خصوصا در مواردی که آدرس آن صفحه به خصوص در وبسایتهای دیگر قرار گرفته باشد!

آموزش ساخت فایل Robots.txt
در صورتی که با استفاده از روش گفته شده، موفق به پیدا کردن فایل روبوت نشدید، پس احتمالا خودتان باید دست به کار شده و یکی ایجاد کنید. برای ساخت فایل Robots.txt تنها کاری که باید انجام دهید این است که یک فایل .txt ایجاد کرده و دستورات مورد نظرتان را وارد کنید. بعد از انجام این کار، فایل را با نام robots.txt ذخیره کنید. در غیر این صورت، میتوانید از ابزارهای مخصوص جهت ساخت فایل روبوت استفاده کنید. مانند tools seo book.
اگر تجربه ساخت فایل Robots.txt را ندارید، پیشنهاد ما استفاده از ابزار گفته شده است. چرا که با استفاده از این ابزارها، درصد خطا مانند غلط املایی کاهش خواهد یافت.
فایل Robots.txt را کجا قرار بدیم؟
فایل ساخته شده را باید در دایرکتوری روت دامنهای قرار دهید که تنظیمات را برای آن در نظر گرفتهاید. به عنوان مثال برای دامنه domain.com، فایل robots.txt باید در آدرس domain.com/robots.txt در دسترس باشد. یا اگر میخواهید تنظیمات برای یک زیر دامنه مانند blog.domain.com اعمال شود، فایل robots.txt باید در مسیر blog.domain.com/robots.txt قابل دسترسی باشد.
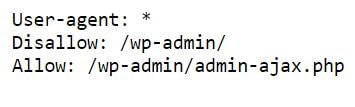
نحوه ویرایش فایل Robots.txt از طریق افزونه یوست
فایل روبات به طور پیش فرض توسط وردپرس ایجاد شده و ظاهری شبیه به کدهای زیر دارد:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
برای ساخت و ویرایش این فایل میتوانید هم به صورت دستی از طریق سرور و هم از طریق افزونه یوست اقدام کنید. در حقیقت آموزش ساخت فایل robots.txt برای وردپرس بسیار ساده بوده و از طریق یک افزونه، انجام خواهد شد. پیشنهاد و توصیه ما استفاده از افزونه Yoast است. برای ویراش این فایل، مراحل زیر را دنبال کنید:
- وارد بخش پیشخوان وبسایت وردپرس خود شوید.
- از منوی سمت راست، روی گزینه SEO کلیک کنید.
- از زیر منوی نمایش داده شده، روی گزینه ابزارها (Tools) کلیک کنید.
- در صفحه نمایش داده شده، روی گزینه ویرایشگر پرونده، کلیک کنید.
- تغییرات مورد نیاز را ایجاد کرده و سپس آنها را ذخیره کنید.
ترفندهای ساخت فایل Robots.txt
هنگام ساخت فایل robots.txt نکات زیر را در نظر داشته باشید تا از ایجاد خطاهای احتمالی جلوگیری کنید:
هر دستور را در یک خط بنویسید
هر خط از دستورات باید در یک خطر جداگانه نوشته شوند. چرا که در غیر این صورت همه چیز مبهم و گیج کننده به نظر میرسد!
نمونه غلط:
/User-agent: * Disallow: /directory/ Disallow: /another-directory
نمونه درست:
*:User-agent
/Disallow: /directory
/Disallow: /another-directory
از (*) برای کوتاه کردن دستورات استفاده کنید
در صورتی که قصد دارید یک دستور روی یک بخش کلی از سایت اجرا شود، بهتر است از عملگرهایی مانند * استفاده کنید. به عنوان مثال برای مسدود کردن دسترسی خزندههای گوگل به بخش محصولات سایت بهتر است که از مدل زیر استفاده کنید:
* : User-agent
?Disallow: /products/t-shirts
?Disallow: /products/hoodies
?Disallow: /products/jackets
نه مدل:
* : User-agent
/*?Disallow: /products
در این مثال، دسترسی گوگل به تمامی URLهایی که در دسته products قرار داشته و حاوی ؟ هستند، مسدود میشود.
از علامت $ برای مشخص کردن پایان یک URL استفاده کنید
زمانی که از علامت $ در انتهای آدرس مورد نظرتان استفاده میکنید، دسترسی گوگل تنها به همان آدرسهایی که با پسوند قبل از $ تمام میشوند، مسدود خواهد شد. به عنوان مثال، در قطعه کد زیر، دسترسی گوگل به آدرسهایی که با pdf تمام میشوند، مسدود میشود. بنابراین فایلهایی که آدرس /file.pdf?id=68937586 دارند، هنوز هم در دسترس گوگل هستند.
* : User-agent
$Disallow: /*.pdf
از هر user-agent تنها یک بار استفاده کنید
اگر قصد دارید برای یک user-agent چند دستور تعریف کنید، نیازی نیست برای هر دستور از user-agent استفاده کنید.
User-agent: Googlebot
/ Disallow: /a
User-agent: Googlebot
/ Disallow: /b
این مدل گرچه غلط نیست و مشکلی به وجود نمیآورد، اما قطعا گیج کننده خواهد بود. پس بهتر است که برای جلوگیری از خطای احتمالی، دستورات را تا حد امکان ساده و کوتاه بنویسید.
از کاراکتر / برای جلوگیری از مسدود شدن صفحات درست استفاده کنید
همانطور که تا به اینجا چندین بار گفتهایم، ساخت فایل Robots.txt اگر درست و اصولی انجام شود، تاثیر خوبی در سئو سایت دارد. به همین مقدار هم اگر کوچکترین اشتباهی هنگام نوشتن دستورات رخ دهد، نتیجه فاجعه بار خواهد بود. به همین خاطر مهم است که از کاراکترهای خاص مانند / و # درست و به موقع استفاده کنید. به عنوان مثال تصور کنید که یک سایت چند زبانه دارید. فرض کنید قصد دارید فعلا دسترسی خزندهها به بخش انگلیسی سایت را مسدود کنید. برای انجام این کار، احتمالا از قطعه کد زیر استفاده میکنید:
* : User-agent
Disallow: /en
اما نتیجه این دستورات، مسدود کردن دسترسی موتورهای جستجو به تمام صفحاتی است که آدرسشان با en شروع میشود.
* : User-agent
/ Disallow: /en
از کامنت برای بهبود خوانایی فایل robots.txt استفاده کنید
اگر در زمینه برنامه نویسی تجربه دارید، حتما میدانید که برای بهبود خوانایی کد، حتما باید از کامنت استفاده کنید. خصوصا اگر قصد دارید فایل را در اختیار کس دیگری قرار داده و یا بعد از مدتی مجددا آن را بررسی کنید. به عنوان مثال:
.This instructs Bing not to crawl our site#
User-agent: Bing bot
/ : Disallow
هر چیزی که بعد از # قرار بگیرد، توضیح اضافه بوده و در نظر گرفته نخواهد شد.
برای هر دامنه یک فایل robots.txt مجزا بسازید
اگر از یک دامنه، چند زیر دامنه دارید، باید برای هر یک از آنها یک فایل robots.txt بسازید. به عنوان مثال یکی برای domain.com و یکی دیگر برای blog.domain.com.
نمونه فایل robots.txt
در ادامه چند نمونه به منظور راهنمایی شما جهت ساخت فایل Robots.txt در اختیارتان قرار میدهیم. هر کدی که نیاز داشتید را کپی کرده و داخل فایل .txt قرار دهید و با نام Robots.txt آن را در دایرکتوری مورد نظرتان ذخیره کنید.
تمام رباتها به همه چیز دسترسی داشته باشند
* :User-agent
: Disallow
تمام رباتها به همه چیز دسترسی نداشته باشند
* :User-agent
/ : Disallow
بلاک کردن یک ساب دایرکتوری (زیربخش) برای تمام رباتها
* :User-agent
/Disallow: /folder
بلاک کردن یک ساب دایرکتوری (زیربخش) برای تمام رباتها به جز یکی از فایلهای داخلی
* :User-agent
/Disallow: /folder
Allow: /folder/page.html
بلاک کردن یک نوع فایل خاص برای تمام رباتها
* :User-agent
$Disallow: /*.pdf
مسدود کردن تمام URLهای پارامتردار فقط برای Googlebot
User-agent: Googlebot
?*/ : Disallow
بررسی فایل robots.txt برای شناسایی خطا
برای اینکه اطمینان حاصل کنید تمام آنچه که در فایل Robots.txt وارد کردهاید، درست و بدون مشکل هستند، باید از بخش ” Coverage” در گوگل کنسول، خطاهای آن را بررسی کنید. برخی از خطاهای رایج مربوط به این فایل و روش رفع آنها را در ادامه بیان کردهایم.
دسترسی به یک URL خاص توسط فایل robots.txt مسدود شده است
این حالت زمانی ایجاد میشود که یکی از URLهایی که در نقشه سایت تعریف کردهاید، توسط robots.txt مسدود شده باشد. اگر نقشه سایت شما درست ایجاد شده باشد و موارد تگ Canonical، no indexed و صفحات ریدایرکت شده را درست تعریف کرده باشید، هیچ صفحهای نباید فایل Robots.txt مسدود شود. اما در صورتی که یکی از صفحات سایت به اشتباه مسدود شده است، میتوانید از ابزار گوگل برای بررسی این فایل استفاده کنید. لینک مورد نظرتان را وارد ابزار کرده، و سپس دستوری که مربوط به آن صفحه است را بررسی کنید.
پیام Blocked by robots.txt
این پیام زمانی ایجاد میشود که یک محتوا از سایت توسط فایل Robots.txt مسدود شده و در حال حاضر ایندکس نشده است. اگر این محتوا مهم است، باید وارد فایل شده و دستور مربوط به آن را حذف کنید. البته قبل از هر چیز اطمینان حاصل کنید که محتوای مورد نظرتان تگ no indexed ندارد.
پیام Indexed, though blocked by robots.txt
این پیام به این معناست که برخی از صفحاتی که توسط فایل Robots.txt مسدود شدهاند، در حال حاضر ایندکس شدهاند. در صورتی که قصد دارید که یک صفحه از فهرست ایندکس گوگل خارج شود، استفاده از فایل Robots.txt راه حل درستی نیست. در این شرایط بهتر است که از تگهای مربوط در بخش هدر صفحه استفاده کنید.
مزایای استفاده از فایل robots.txt
اما ببینیم که به چه دلیل استفاده از این فایل برای وبسایتها اهمیت دارد. اگر چه دلایل متعددی وجود دارد، اما در این جا به دو مورد از مهمترین آنها اشاره خواهیم کرد:
-
بهینه سازی حجم درگیر ترافیک
با استفاده از این ربات، با توجه به محدودیت حجم درگیر ترافیک وب سایت خود، میتوانید آن را در پهنای باند ارائه دهنده سرور، مدیریت کرده و به این شکل ورودی وبسایت خود را در شرایط بهتری قرار دهید. این باعث خواهد شد تا ضمن بهبود سرعت وب سایت شما، از نظر کاربران و گوگل نیز در شرایط بهتری قرار داشته باشد.
-
بهینه سازی استفاده از کراول باجت
شما هر روز سهمیه خاصی از کراول گوگل دارید که آن را به نام Crawl Budget میشناسیم. با حذف کردن صفحات غیرضروری از صفحاتی که میخواهید توسط کراول گوگل خوانده شده و بررسی شوند؛ بهتر خواهید توانست میزان کراول باجت وبسایت خود را مدیریت کرده و بهترین بهرهبرداری از آن را داشته باشید.
وقت آن رسیده که فایل robots.txt برای وب سایت خود را ایجاد کنید
در بالا نگاهی به باید و نبایدها و نحوه ساخت این فایل برای وبسایتها انداختیم. اگر پیش از این به این موضوع نپرداختهاید، وقت آن رسیده که برای نجات شرایط وب سایت خود، به آن ورود کرده و با دقت و البته دانش کافی نسبت به این موضوع، فایل روبوت وب سایت خود را ایجاد کنید!
آینده متعلق به کساییه که به زیبایی رویاهای خودشون ایمان دارن.



دیدگاه ها
سلام لطفا یک نمونه خوب راهنمایی کنید تا در قسمت ویرایش قرار بدیم ابزار ساخت معرفی کردید رو من بلد نشدم اگر امکانش هست کمک کنید
با سلام و احترام خدمت شما
اگه سایتتون وردپرسی هستش میتونین از متن زیر استفاده کنین
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: #
سلام وقت تون بخیر
پلتفرمی هست که بهم کمک کنه،در آموزش کامل و جامع ساخت فایل Robots.txt ؟ اگر پلتفرم یا سایت خاصی هست میشه معرفی کنید ممنون میشم.